
Regulatorní rámec Solvency II vyzývá pojistný trh ke změně chování a k novému přístupu k řízení rizik. Naplnění požadavků Solvency II může mít silný dopad na provoz pojišťovny počínaje systémem řízení, organizační strukturou a nastavením procesů a konče definicí produktů, úpravami zajištění nebo správou aktiv. Podrobné definice výpočtů a povinného reportingu spolu s požadavky na datovou kvalitu a systémové zpracování dat jsou tvrdým oříškem pro IT.
Z praktického pohledu vznikají pro pojišťovny dva základní technické požadavky:
- výpočet solventnosti podle tzv. standardní formule
- naplnění požadavků na povinný reporting
Výpočet standardní formule je definován (především) současnou verzí Implementing Measures, povinný reporting je definován prostřednictvím QRT – Quantitative Reporting Templates. V současné době se diskutují tzv. Interim Measures, tedy požadavky, které jsou podmnožinou těch finálních a které by pojišťovny měly naplnit ještě před ostrým startem platnosti nové regulace (co se týká reportingu, zmiňují Interim Measures počátek roku 2015).
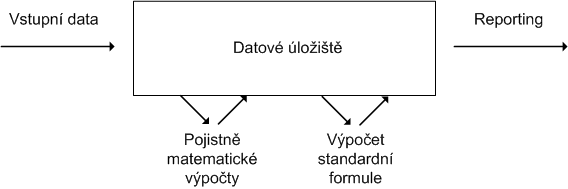
Od těchto dokumentů se odvíjí základní požadavky na IT řešení výpočtů Solvency II. Kromě samotné definice výpočtů a reportů klade Solvency II velký důraz na datovou kvalitu a systémové zpracování dat. Často je používán pojem data lineage – potřeba doložit všechny datové toky, které vedly k finálním výsledkům a reportovaným hodnotám.
Vypadá to jednoduše? V principu ano, ale pojďme se na jednotlivé části podívat trochu podrobněji.
Pojistně-matematické výpočty
Začneme v doméně pojistných matematiků. Tady najdeme nesložitější a výpočetně nejnáročnější operace. Není cílem tohoto článku výpočty podrobně popisovat, spokojíme se pouze s konstatováním, že jejich výstupem je především tzv. fair nebo best estimate hodnota pojistných závazků (technických rezerv) a hodnota těchto závazků pod různými stresy.
Výpočet zmíněných hodnot je srdcem výpočtů Solvency II. Odtud vzejdou hodnoty, které mají zásadní vliv na výslednou solventnost pojišťovny. Zároveň je to metodicky i výpočetně nejnáročnější část celého výpočtu. Pro zpracování těchto výpočtů je potřeba sada specializovaných nástrojů, jejichž komplexita se pohybuje od „dospělých“ modelovacích nástrojů (jako Prophet, Sophas nebo MoSes pro projekci budoucích cash-flow) až po jednodušší excelovská „udělátka“ (které ale pro využití v Solvency II procesu musí splňovat vysokou kvalitu zpracování výpočtů, dat a dokumentace).
I když obsahově jde o náročné výpočty, které jsou výzvou i pro zkušené pojistné matematiky, z pohledu zpracování dat jde paradoxně o poměrně jednoduchou část. Vstupní a výstupní data mají relativně jednoduchou strukturu, vstupní data jsou obvykle dobře dostupná a je třeba se pouze připravit na dlouhé výpočetní časy a velké datové objemy, které souvisí především se stochastickými modely pro životní pojištění.
Výpočet standardní formule
Z matematického pohledu je výpočet standardní formule – nebo spíše dokončení výpočtu standardní formule – mnohem jednodušší než výpočty zmíněné v předchozí kapitole. Jejich obsahem jsou hodnoty jednotlivých rizik definovaných standardní formulí a celkového požadovaného kapitálu (SCR – Solvency Capital Requirement). Tyto hodnoty musí být doplněny o výpočet minimálního kapitálového požadavku (MCR – Minimum Solvency Capital Requirement), sestavení ekonomické bilance a výpočet hodnoty vlastních zdrojů.
Výpočet sám o sobě je v zásadě sada jednodušších či složitějších vzorců, komplikací je však jejich rozsah a vzájemná provázanost. Jednotlivých výpočtů jsou desítky a v souhrnu tvoří rozsáhlý a nepříliš přehledný komplex, ve kterém se snadno může ztratit i odborník na danou problematiku.
A snad ještě složitější je to z pohledu zpracování dat. Vstupů do výpočtu standardní formule je velké množství (mluvíme o stovkách položek) a jde o vstupy značně heterogenní, z různých oblastí a s různou úrovní systémové podpory. A málo není ani výstupů, pokud těmito výstupy chceme pokrýt požadavky na povinný reporting.
Zpracování dat a reporting
Tady už se definitivně dostáváme do domény IT. Ne snad, že by se výše popsané – tedy výpočet standardní formule a potřebné pojistně-matematické výpočty – obešly bez IT podpory, ale v těchto oblastech dominuje odborná stránka a specializované nástroje. A z odborného pohledu, tedy pojistně-matematického, se zdá být vše důležité vyřešeno…
Co ale uvidí IT analytik, který má vyřešit reporting?
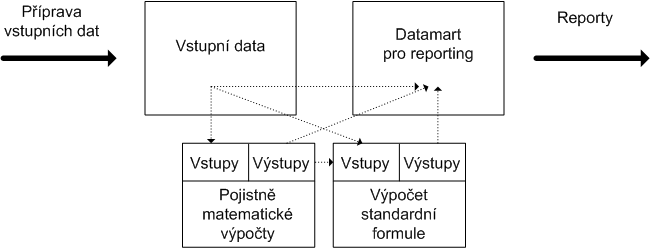
V první řadě uvidí více než padesát reportů definovaných prostřednictvím QRT. Mnohé z těchto reportů jsou značně rozsáhlé a jde spíše o skupinu reportů – reálný počet jednotlivých reportů je tak mnohem vyšší. V dalším kroku zjistí, že k vytvoření těchto reportů potřebuje širší a podrobnější množinu dat, než tu, která stačila pro výpočet standardní formule. Začne také řešit konzistentní uložení všech dat, aby byly naplněny požadavky na doložení zdrojových dat, mezivýpočtů a datových transformací.
jistí ale hlavně, že má před sebou hodně práce. Zůstaneme-li jenom u modelu vstupních dat, mluvíme o desítkách entit a stovkách atributů. Udržení konzistence tohoto modelu, tedy nezdvojování vstupů a jejich logické a přehledné členění, bude hlavolamem s velmi složitým zadáním. Stejně jako dořešení datových toků k výpočtům a finálnímu reportingu.
Pak ovšem přijde to opravdu složité – samotná příprava vstupních dat. Zatímco model vstupních dat, návazné výpočty a tvorba reportů je generický problém, daný požadavky Solvency II, příprava vstupních dat je vždy originál, daný podmínkami konkrétní pojišťovny. Pokud by IT analytik chtěl požadavky na datovou kvalitu a systémovost zpracování naplnit bezezbytku, ve většině pojišťoven zjistí, že by potřeboval zásahy do provozních systémů s mnohdy až absurdní pracností.
Reálné řešení tedy bude kombinací úprav a rozšíření provozních systémů a manuální přípravy dat tam, kde úplná systematizace a automatizace nedává reálný smysl. Manuální vstupy bude ovšem třeba také ošetřit, měly by být plně auditované a vynucované striktně nastaveným workflow.
Kompletní implementace výpočtů a reportingu
To, že nový výpočet solventnosti je o několik řádů složitější než ten původní, je zřejmé už mnoho let. A očekávání náročnosti jeho realizace je tomu úměrné. Je však třeba si uvědomit, že jedna úloha je realizovat takový výpočet jednorázově na ad-hoc připravených datech, druhá úloha je dostat vše do pravidelného režimu automatizovaného zpracování dat, jejich konzistentního ukládání a reportování. Tato úloha může být stále na pokraji zájmu, ale náročnost její realizace je srovnatelná s úlohou první a v případě nekompromisního přístupu pak tato náročnost může být daleko vyšší.
Nezapomínejme také, že standardní formule může být nahrazena částečným nebo úplným interním modelem (z pohledu implementace je lépe říct doplněna – standardní formule se musí počítat a reportovat i v tomto případě). Další výpočty lze očekávat v rámci ORSA (Own Risk and Solvency Assessment). Je třeba vytvořit systém řízení rizik a pro ten bude vhodné připravit systém interního reportingu.
To vše ještě IT řešení pro Solvency II, už tak velmi náročné, dále zesložiťuje. Dobrá zpráva je, že pokud povinné výpočty a reporting budou zpracovány systémově a korektně, jejich rozšíření na kompletní podporu interního řízení rizik je relativně snadné – půjde jen o doplnění stejné architektury o další výpočty, data a reporty. Tak se mohou zúročit nemalé náklady vložené do základních výpočtů a regulatorního reportingu.















