
Výpadek IT může vyjít hodně draho. Svědčí o tom časté požadavky na řešení Disaster Recovery (obnova po havárii) pro aplikace, data a prostředí. Firmy si uvědomují, že i když je pro většinu z nich IT nevýdělečnou činností, mají tyto procesy vysokou míru důležitosti až závislosti. Její selhání nebo nedostatek se projeví právě v oblastech, které již výdělečné jsou.
Mnoho podniků však při pořizování a rozhodování o Disaster Recovery tápe. Na jedné straně chtějí zabezpečit chod podnikových technologií, na straně druhé ušetřit. Výběr vhodného řešení pro Disaster Recovery je více věcí taktického provozního rozhodnutí než samotného IT.
Každá cesta začíná prvním krokem
V první řadě je třeba zjistit, jakou roli ve vaší společnosti IT oddělení hraje a jak na něm je, nebo není, závislá výdělečná část firmy. K takovémuto zjištění by měla pomoci Analýza dopadů (Business Impact Analysis, BIA). Ta sestává z technik a metod, pomocí kterých se hodnotí, jaké dopady by na organizaci a další zainteresované strany mělo narušení dodávek klíčových produktů nebo služeb organizace. Součástí BIA je rovněž stanovení minimálních úrovní zdrojů potřebných pro obnovení kritických činností ve stanovených časech a úrovních.
Při hodnocení dopadů na organizaci v případě narušení kritických činností se berou v úvahu spíše následky než příčiny. Dopady na organizaci a jejich vývoj v čase se posuzuje dle vhodných vodítek. Ta se pro finanční instituce budou lišit od vodítek orgánu státní správy. Vodítka pro hodnocení dopadů mohou být například finanční ztráta, dopad na dodávky služeb, poškození nebo ztráta pověsti, nesplnění zákonných nebo regulačních povinností a podobně.
Závěry z analýzy dopadů společně s hodnocením rizik narušení kritických činností organizace jsou základem pro strategie řízení kontinuity činností. Ty umožňují identifikovat různé varianty a způsoby obnovy kritických činností organizace v případě jejich narušení. Analýza dopadů by měla být přezkoumávána v pravidelných intervalech nebo při podstatných změnách v organizaci a prostředí.
Nyní již víme, kolik bude stát výpadek služeb poskytovaných IT oddělením. Je zřejmé, že ne každá poskytovaná služba je pro společnost stejně kritická a nemusíme tedy ke všem službám přistupovat stejně. Měli bychom si poskytované služby rozdělit do několika úrovní, podle jejich kritičnosti a dopadu na fungování firmy. Tímto jednoduchým rozdělením můžeme ve výsledku uspořit značnou část finančních prostředků, protože je velmi pravděpodobné, že kritických systémů bude mnohem méně než nekritických. Po tomto rozdělení do jednotlivých skupin je třeba pro každou z nich určit její RPO a RTO.
RPO aneb Kdy jsem naposledy zálohoval?
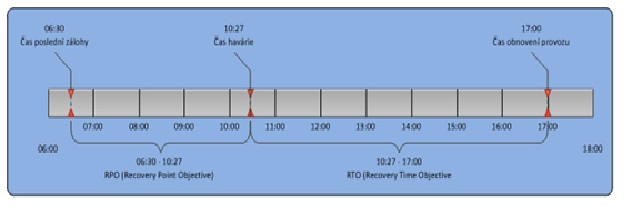
RPO (Recovery Point Objective) je čas, do kterého se budete muset v případě havárie vrátit, nebo pro zjednodušení jde o čas, ze kterého máte poslední zálohu dat. Pro lepší představivost použijeme obrázek 1. Na něm je jako modelový příklad uveden čas havárie 10:27 a čas poslední zálohy 6:30 stejného dne. Recovery Point Objective je tedy v našem případě 3:57 hod. Znamená to, že jsme o tato data přišli a již je nebudeme, s největší pravděpodobností, schopni jakkoli obnovit.
RTO aneb Kdy už to bude zase fungovat?
RTO je druhý parametr viditelný na obrázku 1. Tentokrát jde o Recovery Time Objective, jedná se o čas, který je zapotřebí k tomu, aby postižená služba (aplikace) byla znovu dostupná. V praxi lze tento čas velmi obtížně stanovit s přesností na jednotky minut (ale i takové Disaster Recovery prostředí je možné vybudovat). Například se může jednat o dojezdovou dobu zodpovědného pracovníka nebo o čas nutný k opravě vadného zařízení, instalaci operačních systémů a aplikací. V neposlední řadě se též jedná o dobu potřebnou k obnovení dat z poslední zálohy.
Jaké hodnoty RPO a RTO zvolit?
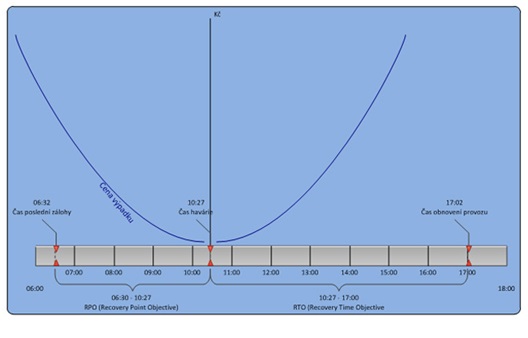
Nejprve je třeba se vrátit k analýze dopadů a k její finanční části. Z této analýzy zjistíme, kolik peněz stojí každá hodina (případně minuta) nedostupnosti té které služby a také kolik peněz stojí ztráta dat. Pokud bychom si takovouto analýzu převedli do grafu, můžeme dostat výsledek podobný, jako je na obrázku 2. Z toho je jasné, že čím méně dat ztratím a čím rychleji je možné po havárii obnovit provoz, tím méně peněz to stojí.
Nyní přichází čas, kdy se lze obrátit na dodavatele IT řešení se žádostí o první indikativní nabídky na zajištění dostupnosti provozovaných služeb. Nabídky by měly být vypracovány variantně pro různě velké RTO a RPO.
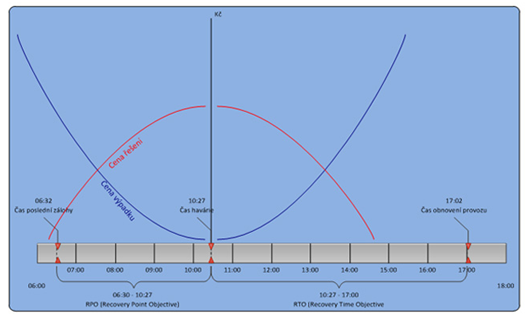
Po obdržení nabídek si jejich cenu opět velmi jednoduše promítneme do již známého grafu, tak jak je znázorněno na obrázku 3. Tím dostaneme průsečíky mezi cenou řešení Disaster Recovery a ztrátou v případě výpadku.
Zjednodušení na závěr
Pro celkové zjednodušení této tématiky se osvědčila paralela s úrazovým pojištěním. Vždy záleží na zvážení toho, co firmě hrozí a jak dobře se proti tomu nechá pojistit. S řešením Disaster Recovery je to stejné, jen s tím rozdílem, že se nepojišťujete pro případ úrazu, ale pro možnost havárie serveru nebo třeba diskového pole.
Zároveň se nesmí zapomenout, že veškeré zde uvedené údaje z oblasti analýz, ale i nabídek je třeba zpracovávat s ohledem na délku životního cyklu dotčených zařízení a do výpočtů tedy zahrnout náklady CAPEX a OPEX (investiční a provozní).
















