Solvency II, zásadní reforma regulace evropského pojišťovnictví nezmění jen regulatorní praxi, ale přinese dramatické změny v samotném fungování pojišťoven, například v oblasti jejich řízení rizik a kapitálu a dramaticky také zamává s nastavením dat a systémů. Jak ale zabránit tomu, aby vaše IT při její implementaci zešílelo?
Regulatorní rámec Solvency II vyzývá pojistný trh ke změně chování a k novému přístupu k řízení rizik. Naplnění jejích požadavků může mít silný dopad na provoz pojišťovny počínaje systémem řízení, organizační strukturou a nastavením procesů a konče definicí produktů, úpravami zajištění nebo správou aktiv. Podrobné definice výpočtů a povinného reportingu spolu s požadavky na datovou kvalitu a systémové zpracování dat jsou tvrdým oříškem pro IT.
Z praktického hlediska musejí pojišťovny vyřešit dva základní technické požadavky:
- výpočet solventnosti podle standardní formule
- naplnění požadavků na povinný reporting
Výpočet standardní formule je definován hlavně současnou verzí Implementing Measures, povinný reporting je definován prostřednictvím QRT – Quantitative Reporting Templates. V současné době se navíc dolaďují tzv. Interim Measures, tedy další požadavky, které mají pojišťovny naplnit ještě před ostrým startem platnosti nové regulace.
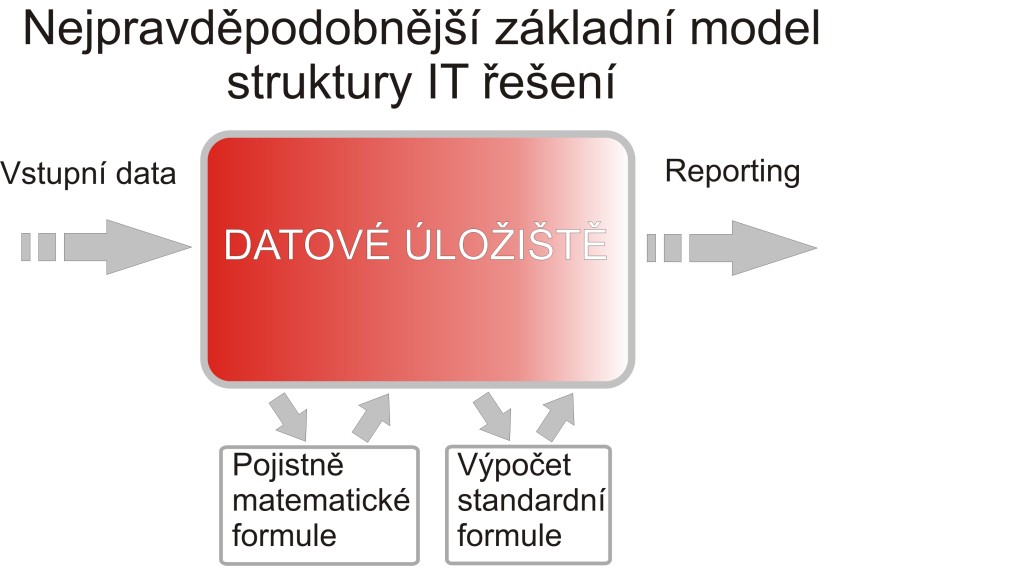
Od těchto dokumentů se odvíjejí základní požadavky na IT řešení. Kromě samotné definice výpočtů a reportů klade směrnice důraz na datovou kvalitu a systémové zpracování. Z čistě matematického pohledu došlo oproti původnímu modelu „jen“ k jeho zesložitění o několik kroků. Co ale uvidí váš skutečný IT analytik, který má vyřešit reporting?
V první řadě to bude více než padesát reportů definovaných prostřednictvím QRT. Mnohé z nich jsou značně rozsáhlé a jde spíše o skupiny reportů – reálný počet jednotlivých reportů je tak mnohem vyšší. V dalším kroku zjistí, že k vytvoření těchto reportů potřebuje širší a podrobnější množinu dat, než tu, která stačila pro výpočet standardní formule.
To ale není pro analytika jediný oříšek, bude muset také řešit konzistentní uložení všech dat, aby byly naplněny požadavky na doložení zdrojových dat, mezivýpočtů a datových transformací. Analytik ale hlavně zjistí, že má před sebou hodně práce. Zůstaneme-li jenom u modelu vstupních dat, mluvíme o desítkách entit a stovkách atributů. Udržení konzistence tohoto modelu, tedy nezdvojování vstupů a jejich logické a přehledné členění, bude hlavolamem s velmi složitým zadáním. Stejně jako dořešení datových toků k výpočtům a finálnímu reportingu.
Po bezesných nocích a hodinách a hodinách práce ale nakonec teprve přijde to opravdu složité – samotná příprava vstupních dat, o té ale zase někdy příště.
Zaujala vás problematika? Více informací naleznete v podrobné analýze celého problému v článku Solvency II – komplexní přístup ke zpracování dat na webu www.adastra.cz.