Umělý člověk a stroje napodobující lidskou mentální činnost tak, že bude nerozeznatelná od skutečných projevů lidského ducha, trápí lidskou fantazii prakticky odjakživa. Nad UI se zamýšlely celé pluky snílků od antiky až do dnešních dnů. Jak dlouhá cesta vedla od prvních nesmělých, nebo naopak možná až příliš smělých pokusů až k Watsonovi od IBM?
Jak vůbec umělou inteligenci definovat? Americký vědec Marvin Minský, který svůj život zasvětil zkoumání fenoménu AI, prohlásil: „Umělá inteligence je věda o vytváření strojů nebo systémů, jež budou při řešení určitého úkolu užívat takového postupu, který bychom (při zachování anonymity původce) považovali za projev jeho inteligence.“ Taková definice, ač se to možná nezdá, pochopitelně není vycucána z prstu, ale staví na relativně pevných základech v podobě Turingova testu. Ten vytvořil v roce 1950 britský matematik Alan Turing, aby bylo možné vůbec nějak jednoznačně určit, jestli nějaký program může být inteligentní.
Divadlo za zavřenou oponou
Celý test stojí na jednoduché imitační hře. Té se účastní tři hráči, přičemž druhý hráč se snaží napodobovat činnost prvního takovým způsobem, aby ve výsledku třetí účastník, který jim zadává úkoly, nepoznal, kdo co provádí. Pokud bude totiž počítač v roli druhého hráče spolupracovat inteligentně a podávat relevantní odpovědi, mohl by třetí účastník na základě pouhých výstupů dojít k závěru, že komunikuje se skutečným člověkem. V takovém případě bychom měli co dělat s regulérní umělou inteligencí. V praxi to může fungovat třeba tak, že program má databázi s obsahem klíčových slov, s ním porovnává slova ve větě vašeho dotazu. Pokud nějaké klíčové slovo ve větě nalezne, pokusí se k němu z tabulky reakcí přiřadit odpovídající odpověď a v případě úspěchu ji použije.
Turingův test samozřejmě není úplně bez chyby, protože hodnotí spíše schopnost myšlení předstírat, ale vůbec například nebere v potaz kreativitu. Celý test je tedy příliš jednostranný a místo o skutečné inteligenci vypovídá o schopnosti přístroje přesvědčivě lhát (napodobovat). V tomto smyslu je jednostranná i Minského definice. Tady bychom ovšem neměli zapomínat ještě na jednu důležitou věc, dalším podstatným rysem inteligentních systémů je totiž schopnost vytvářet vnitřní model okolního světa a také umění s ním pracovat. Pokud pak zadáme libovolný počáteční a cílový stav, měl by být modul umělé nteligence schopný sestavit na základě svého vnitřního modelu takovou posloupnost akcí, aby pomocí nich došel k relevantnímu cíli.
Slabina Turingova testu?
Hlavní chybu Turingova testu hezky ilustruje takzvaný argument čínského pokoje. Zkusme si představit uzavřenou místnost, která je naplněna velkým množstvím čínských textů. Do ní pak umístíme průměrného Evropana, který čínštinu neovládá, ale ví, ve které přihrádce může nalézt na základě povahy dotazu relevantní odpověď. Pokud bude komunikace probíhat písemnou formou tak, že dotyčný vždy pouze opíše to, co se nalezne v daném textu, mohl by se tazatel domnívat, že dotyčný jazyku bez problému rozumí. Skutečnost je ovšem taková, že náš pomyslný knihovník pouze mechanicky pracuje s pro něj nesrozumitelnými symboly, takže jeho výstup o jeho skutečné inteligenci nic nevypovídá. Stejnou práci zvládne vykonat i úplně nemyslící stroj (a také to často činí). Argument čínského pokoje objevil filosof John Searl v roce 1980.
Pomalu se dostáváme do míst, kde se nám začínají jednotlivé koncepce umělé inteligence maličko rozcházet. Slabiny Turingova testu totiž vytvořily ve světě
umělé inteligence první schizma – co lze chápat jako AI (Artificial Inteligence), a co ještě (už) nikoliv?
Obecně se tak začala rozlišovat umělá inteligence slabá a silná. S tou první se můžeme setkat i v běžném životě ve formě nejrůznějších jednoúčelových expertních systémů. Ty jsou prakticky dvojího druhu, diagnostické a plánovací.
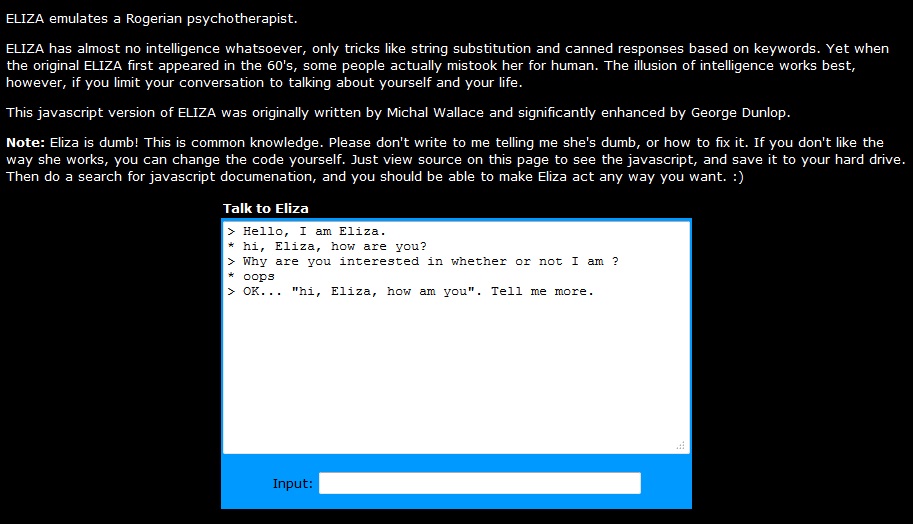
První z nich dělá to, že na základě předdefinovaných hypotéz porovnává vstupy s daty ve vlastní databázi a následně vybere nejlépe korespondující řešení. Jedním z nejbanálnějších příkladů může být stanovení diagnózy nemocného pacienta podle subjektivních příznaků. V momentě, kdy systém nasbírá dostatek vstupních dat, zvolí jedno z řešení, které má uložené ve své databázi. Takto pracuje například dnes již trochu zastaralý lékařský expertní systém MYCIN nebo experimentální automatizovaná psychoanalýza ELIZA.
Až vám bude někdy smutno a nebudete mít zrovna co na práci, zkuste si s ní také popovídat, je to docela legrace, naleznete ji třeba zde. Neobejdete se však bez elementární znalosti angličtiny, protože jiné jazyky Eliza neumí a nejspíš také ani umět nebude. Naopak plánovací expertní systémy slouží k vyřešení takové úlohy, kdy známe počáteční stav a cíl řešení a zajímá nás posloupnost ideálních kroků (rychlost, cena, čas), jež nás mají dovést ke kýženému výsledku. S takovými systémy se setkáme v širokém spektru oblastí od v zásadě primitivních navigací až po složité programy k odvozování struktur chemických látek na základě histogramu ze spektrometru pro jadernou magnetickou rezonanci.
Expertní systémy dneška a jak do toho zapadá Watson
Většina expertních systémů dneška má spíše hybridní (kombinovanou) povahu, to znamená, že používají jak plánování, tak diagnostiku. Typickým modelem může být například výukový program, který nejprve diagnostikuje studentovy znalosti a podle výsledku naplánuje jeho další nutné vzdělávání.
Potíž je v tom, že jde ve většině případů o nějaký kompromis. Expertní systémy, které se dnes používají, zvládají po odladění pracovat s počáteční databází, ale při učení se novým věcem vznikají potíže. Jinými slovy, pokud jsme nestandardním způsobem rozšířili, nebo vyměnili databázi, přestává si s ní expertní systém vědět rady a začíná poskytovat nesmyslné odpovědi.
Watson v tomto případě představuje další evoluční stupeň, neboť si je schopen (teoreticky) poradit v libovolném prostředí. Watson je schopný najít správné korelace mezi informacemi a dynamicky určit vztahy v obrovském množství dat. V jistém smyslu jde o předvoj, počítačové systémy budoucnosti budou podobně jako Watson stavěny tak, aby se učily zacházet s informacemi jako lidé, tedy budou je zpracovávat opakovaně a vyhodnocovat pokaždé ve vztahu k novým datům. Vedle tohoto analytického přístupu je zde ještě jedna důležitá změna, Watson totiž dokáže stanovit míru své důvěry v předpokládanou odpověď.
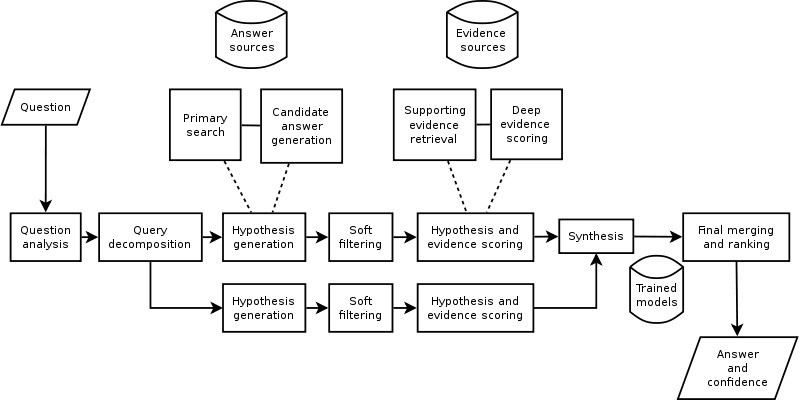
Co přesně Watson představuje a jak funguje? Watson je systém navržený společností IBM, který vyhrál hru Jeopardy proti svým největším konkurentům. Podle slov IBM je Watson optimalizovaný pracovní systém navržený k provádění komplexních analýz, který je výsledkem spojení paralelně zapojených procesorů Power7 a odpovídacího softwaru DeepQA.
Watson umí pracovat s přirozeným jazykem, analyzovat a znázorňovat informace, argumentovat, učit se a odpovídat na otázky.
Jak to bylo s Jeopardy!
V americké soutěži, která je ekvivalentem našeho Riskuj!, byl Watson vybavený předem nahranou databází (která čerpala z Wikipedie a několika dalších zdrojů) a postaven před dva nejlepší dosavadní hráče v soutěži. Jeho úkolem bylo odpovídat na otázky s otevřeným obsahem (situace, kdy není omezené téma otázky) položené v přirozeném jazyce.
Systém nejprve rozložil otázku, následně analyzoval nápovědu v přirozeném jazyce a na základě sémantického porovnání s uloženými informacemi vygeneroval kandidáty na správnou odpověď (hypotézy). Další bod spočíval v sebekontrole, systém odpovídal pouze tehdy, když měl dostatečnou míru jistoty. Samotným otázkám Watson nerozuměl, což se v soutěži dobře ukázalo na příkladu s Torontem.
Jaké technologie Watson používá:
- zpracování přirozeného jazyka
- vybavování informací
- reprezentace znalostí a uvažování o nich
- strojové učení
Co přijde po Watsonovi?
Přes všechna plus je Watson zatím reprezentantem tzv. slabé UI, což je případ, kdy se stroje chovají jako inteligentní bytosti, další výzvou nejen pro IBM bude stroj, který bude skutečně myslet.