Superpočítač Watson navržený k provádění komplexních analýz, který je výsledkem spojení paralelně zapojených procesorů Power7 a odpovídacího softwaru DeepQA, se při pokusu naučit jej slangový jazyk naučil hovořit sprostě.
K problému došlo kvůli tomu, že systém nedokáže rozlišit pragmatické nuance v řeči a klidně použije vulgární výraz, tam, kde jej má zařazený jako synonymum pro nějaký neutrální termín.
Aby Watson lépe porozuměl slangovému jazyku, naučili jej inženýři z IBM databázi výrazů z internetového slovníku Urban Dictionary, tyto výrazy si systém sám doplnil některými pojmy, které nalezl na Wikipedii.
Databáze Urban Dictionary nakonec musela být z Watsona úplně odstraněna a navíc byl doprogramován filtr, který brání tomu, aby systém používal vulgarity naučené na Wikipedii, která slouží jako jedna z hlavních zásobáren obecných vědomostí systému. Informaci médiím prozradil Eric Brown, jeden z vědců, kteří dohlížejí na vývoj DeepQA.
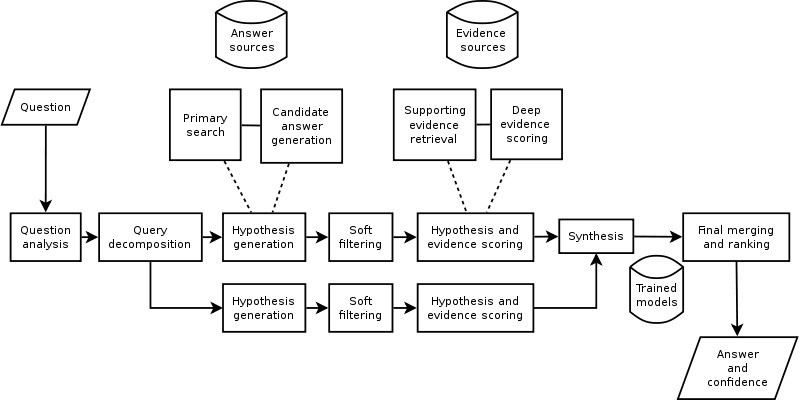
Watson umí pracovat s přirozeným jazykem, analyzovat a znázorňovat informace, argumentovat, učit se a odpovídat na otázky. V americké soutěži Jeopardy!, kde se systém poprvé vyznamenal před veřejností, byl Watson vybavený předem nahranou databází a postaven před dva nejlepší dosavadní hráče v soutěži. Jeho úkolem bylo odpovídat na otázky s otevřeným obsahem (situace, kdy není omezené téma otázky) položené v přirozeném jazyce.
Systém nejprve rozložil otázku, následně analyzoval nápovědu v přirozeném jazyce a na základě sémantického porovnání s uloženými informacemi vygeneroval kandidáty na správnou odpověď (hypotézy). Další bod spočíval v sebekontrole, systém odpovídal pouze tehdy, když měl dostatečnou míru jistoty. Samotným otázkám Watson nerozuměl, což se v soutěži dobře ukázalo na příkladu s Torontem. Watson během své práce využívá strojové učení, zpracování přirozeného jazyka, vybavování a reprezentaci znalostí a uvažování o nich.